What happens when Java source code gets compiled?
Chances are you already know this bit: The Java compiler compiles the human-readable source code - to machine-readable byte code. This bytecode has been produced without special hardware in mind. Instead, it runs on a kind of virtual machine. In other words, it works on a computer that doesn't exist as hardware but has been implemented in software. In theory, it's feasible to build a CPU that executes Java bytecode natively. Such CPU have been constructed in the past; by the look of it, a few of them sell even today. For instance, Jazelle was part of many ARM processors; however, implementing Java in hardware never became a significant commercial success. In fact, the dominance of Windows and Unix operating system prevented this. Java CPUs usually were secondary co-processors, adding to the cost of the hardware, but adding little value to most users. Furthermore, Java bytecode seems to be surprisingly sophisticated. As far as I know, no Java CPU ever implemented the entire instruction set.
A quick introduction to Java bytecode
As a matter of fact, Java bytecode is the outcome of the compilation of a Java program, an intermediate representation of that program which is machine-independent. The Java bytecode gets processed by the Java virtual machine (JVM) instead of the CPU. Hence, It is the JVM job to make the required resource calls to the CPU in order to run the bytecode. We can also perceive Java byte code as an intermediate language between machine code and Java that follows the stack-oriented paradigm, which makes it particularly easy to implement a virtual machine. Have you ever heard of reverse polish notation? Then you already know the idea. In this notation instead of writing:
Println(7+8);
7 8 + println
7 // push 7 on the stack
8 // push 8 on the stack
+ // consume 7 and 8 and push the result on the stack
println // consume the result and print it
iconst_7
iconst_8
iadd
println // push the method pointer on the stack
invokestatic // consume the method on the stack and invoke it
Whats is the JVM Stacks and Stack Frames
Let's imagine that when an application get loaded by the JVM, it initiates a thread that has a private "Stack", built at the same time as the thread. This stack stores frames. A JVM stack is similar to the stack of a traditional language such as C: it contains local variables and partial results, and plays a part in method invocation and return. Because the JVM stack cannot be (officially!) manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a JVM stack does not need to be contiguous. Most programming language store local variables on the subroutine stack. Java bytecode go one step further by putting everything on the stack. Here I explain the idea with a step-by-step walkthrough. See the stack grow and shrink during the execution of 7 8 + println:
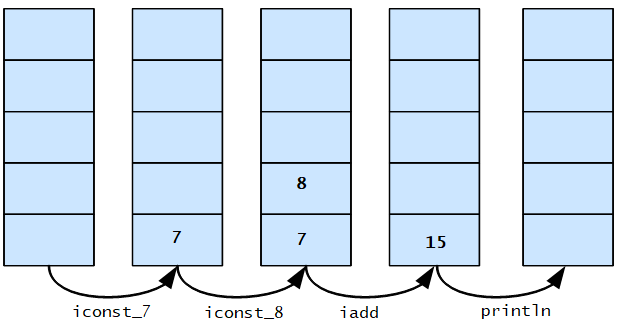
- We start with an empty stack.
- iconst_3 puts the integer value 3 on the first free slot of the stack.
- The next instruction is iconst_4. It puts a 4 on the first free slot of the stack. That's the slot above the 3.
- The add instruction take the two upper-most values from the stack and adds them. After that, it puts the result on the stack again.
- The println() method takes the upper-most value from the stack and prints it to the system console. After that, the stack is empty again.
